Z80での10の高速除算方法 [Z80]
今回はtwitterで見かけたZ80で10で割る処理に関するお題について書いてみます。
お題としてはZ80で100未満の数値を10で除算処理する場合、如何に高速にできるか?というもので
Breg ÷ 10 = Hreg ... Areg
という処理です。
具体的な処理例も挙げられていて次の処理を高速化できるか? という問題です。
100要素分の回答の配列から引っ張るのが一番速いですがそれは無しという条件付きです。
尚、以下に示す各処理は0..99の入力に対するリターン値(AregとHreg)が全て同じであることを確認済みのものです。
処理例
上記の処理内容を見ると通常の割算処理のループを展開したような形になっています。
ループが展開されているので被除数が小さい場合には上位桁の演算をスキップするショートカット方式を最初に思いつきました。
ショートカットすることで
0~39なら -54clk
40~99なら+18clk
となり平均すれば-10.8clk分速くなりそうです。
最初に思いついたショートカット方式
しかし、既に下記のバイナリサーチのような処理案(「引き放し法」と言うそうです)が出ていて処理内容が複雑そうですが確かに速そうです。
引き放し法
ぱっと見は処理内容が解り辛いですが、10 x (2のべき乗) の大きい方(80)から引いていき(キャリが出たら次は足す)、10未満になったら終了するような処理が見えてきます。
最初に書いた処理例では比較(CP)で確認後減算(SUB)していますが、比較による確認無しに減算し、マイナスになっても元に戻さず(だから「引き放し法」)次に半分の値を足すことで結果として半分の値を引いたのと等価になるというものです。
しかし、入力値の条件が100未満なので80を引けた場合、直後に40を引いているのは無駄なように見えます。
80を引いた後は0..19の範囲内なので10を引けるかのチェックをした方が早く収束するはずなので改善してみたものが下の処理です。
引き放し法の改善案
発想を変えて、お題がZ80なのでBCD関連の命令をうまく利用できないか考えてみた結果が次の処理です。
★追記 2019/07/13 {
思考の順番としては100要素の回答テーブルの各要素の規則性は単純なのでもっと短いテーブルにできないものか?という発想から考えた結果として上位ニブルに対するBCDテーブルに行き着きました。
}
RRD命令のクロック数が多いのが気になりますがこれも結構速そうですね^^
気合を入れれば平均クロック数を算出して上の処理と比較できますが夜の作業としては他の作業をしたい(上の処理は分岐確率が50%でないところがあるので更にややこしい)
今時のマイコンであれば統合開発環境内で実行時のクロック数はシミュレータですぐに確認できるのですが、Z80のシミュレータで実行クロック数を確認できるものを少し探しましたが見当たりませんでした。
0..99をループで回し開始/終了時にI/O命令を実行してロジアナで確認することはある程度容易にできますが、それもやぼったいので、クロック数をモニタできるシミュレータが見つかったら比較してみたいと思います。
現時点で最新の高速処理案
★追記 2019/08/01
このブログの読者にはあまり人気が無かったこのページのアクセスが最近多くなりました。
yasuokaの日記: Z80における定数10の除算は、商と余りのどちらを先に求めるべきか
関連の書込み記事からのアクセスのおかげのようです^^
51/512倍することで商を出す手法で末尾に ret を加えると108clk(ステート)で上記のもの(118clk)より高速です(上記のものもRRD命令部をシフト化して数clkの短縮は可能ですが)。
今回の問題では入力範囲が0..99なのでこのような分数演算の手法では誤差を1%未満にする必要があります。私も13/128でやってみたところ誤差が1%以上なので回答が途中からズレた結果になりました。
また、整数演算なので誤差が1%未満であっても誤差の範囲内の変動で回答が影響を受けないように inc a で微調整されています。
普通に考えると16bitでシフトしたいところですが、なんと8bitのシフトや演算で処理を完結しています・・すばらしい!
私も新たなアイディアを思いついたら追記したいと思います。
★追記 2019/08/02
アイディアが浮かんだので試してみた結果をメモしておきます。
今回、複数のアイディアを盛り込み、結果として上記の分数方式(108clk)より4clk短縮(104clk)できました。(^^)/
★変更 2019/08/03 {
yasuokaの日記: Re:Z80における定数10の除算は、商と余りのどちらを先に求めるべきかの記事がアップされ剰余を先に求める方法で103clk(最後にretを追加した場合)達成とのこと。
今回追記した処理に関してもまだ少しのりしろがあったので一部見直し103clkになりました^^
}
今回適用した主要なアイディアとしては、少数演算の使用と上位/下位のnibleを逆転することによる4bitシフト処理の省略です。
後者についてはピンと来ないかも知れませんが以下に概要を説明します。
小数点で0.1倍した改善処理
★追記 2019/12/27
下記の変更で3ステート速くなり、サイズも1バイト小さくなります。
★追記 2021/12/03
上記の変更でEregが非破壊になりました。更にCregを使用している3箇所をHreg使用に変更することでCregも非破壊にできます。
★追記 2019/08/07
分数方式についての考察を少し書いてみます。
初めに前回の小数点方式について動作を判り易く図解してみます。
下図で一番上に書いてある「x 1.5」の行は被除数を1.5倍したものです。
0.1を2進数で表すと上記のように「0001100110011・・・」の循環小数になるので「1.5倍」の数を4ビットずつシフトしながら無限回並べたものの合計になります。
上の小数点方式の説明で「上位/下位ニブルの逆転処理」と書いた部分でキャリーを足している対象は正確に言うと下図の「整数部分」になります。
因みに4bit周期の循環小数なのでうまくやれば誤差無しに計算可能で(循環部で桁上りした場合、下の桁からも必ず桁上りしてくるので)、小数点部分を正確に求められれば、小数点の上位3bitの2倍と8倍を足すことで余りの値も計算結果から求められるはずなのですが、
の理由から断念しました。
話を分数方式に戻すと分母が2のべき乗の場合、分子のビットパターンは結局上記の0.1の循環小数と同様になり(分母が2のべき乗なら分子は0.1の循環小数のパターンをシフトしたものの近似になるのは当然)、処理内容は前回書いた小数点方式とほぼ同様になります。
試しに 25.5 / 256(1バイトなので判り易い)を例にすると下図のように1.5倍したものを RLCA で4回左シフトし、整数部は下位4bitに折り返した形になります(折り返し部分は不要なのですが、上の小数点方式の観点で見れば、演算精度を上げる方向に作用するのでワザワザ削除する必要はない)。
シフト前とシフト後の値の合計を取り、発生したキャリーを整数部に加える処理となり、前回書いた小数点方式と処理内容は同じになります。
小数点方式も同様ですが(ウルトラCのアイディアがあれば)循環小数点部分の処理の高速化については検討の余地があるかもしれません。
★追記 2019/09/16
「Z80における2進→BCD変換」というお題を見つけたのでWeb上のMSX環境で凸撃兵さんが作られたのものを改造してMSXPen環境で確認してみました。
★追記 2023/04/22
下記の記事で 8bit 符号無し整数の高速な乗算方法を提案しました。
お題としてはZ80で100未満の数値を10で除算処理する場合、如何に高速にできるか?というもので
Breg ÷ 10 = Hreg ... Areg
という処理です。
具体的な処理例も挙げられていて次の処理を高速化できるか? という問題です。
100要素分の回答の配列から引っ張るのが一番速いですがそれは無しという条件付きです。
尚、以下に示す各処理は0..99の入力に対するリターン値(AregとHreg)が全て同じであることを確認済みのものです。
|
上記の処理内容を見ると通常の割算処理のループを展開したような形になっています。
ループが展開されているので被除数が小さい場合には上位桁の演算をスキップするショートカット方式を最初に思いつきました。
ショートカットすることで
0~39なら -54clk
40~99なら+18clk
となり平均すれば-10.8clk分速くなりそうです。
|
しかし、既に下記のバイナリサーチのような処理案(「引き放し法」と言うそうです)が出ていて処理内容が複雑そうですが確かに速そうです。
|
ぱっと見は処理内容が解り辛いですが、10 x (2のべき乗) の大きい方(80)から引いていき(キャリが出たら次は足す)、10未満になったら終了するような処理が見えてきます。
最初に書いた処理例では比較(CP)で確認後減算(SUB)していますが、比較による確認無しに減算し、マイナスになっても元に戻さず(だから「引き放し法」)次に半分の値を足すことで結果として半分の値を引いたのと等価になるというものです。
しかし、入力値の条件が100未満なので80を引けた場合、直後に40を引いているのは無駄なように見えます。
80を引いた後は0..19の範囲内なので10を引けるかのチェックをした方が早く収束するはずなので改善してみたものが下の処理です。
|
発想を変えて、お題がZ80なのでBCD関連の命令をうまく利用できないか考えてみた結果が次の処理です。
★追記 2019/07/13 {
思考の順番としては100要素の回答テーブルの各要素の規則性は単純なのでもっと短いテーブルにできないものか?という発想から考えた結果として上位ニブルに対するBCDテーブルに行き着きました。
}
RRD命令のクロック数が多いのが気になりますがこれも結構速そうですね^^
気合を入れれば平均クロック数を算出して上の処理と比較できますが夜の作業としては他の作業をしたい(上の処理は分岐確率が50%でないところがあるので更にややこしい)
今時のマイコンであれば統合開発環境内で実行時のクロック数はシミュレータですぐに確認できるのですが、Z80のシミュレータで実行クロック数を確認できるものを少し探しましたが見当たりませんでした。
0..99をループで回し開始/終了時にI/O命令を実行してロジアナで確認することはある程度容易にできますが、それもやぼったいので、クロック数をモニタできるシミュレータが見つかったら比較してみたいと思います。
|
★追記 2019/08/01
このブログの読者にはあまり人気が無かったこのページのアクセスが最近多くなりました。
yasuokaの日記: Z80における定数10の除算は、商と余りのどちらを先に求めるべきか
関連の書込み記事からのアクセスのおかげのようです^^
51/512倍することで商を出す手法で末尾に ret を加えると108clk(ステート)で上記のもの(118clk)より高速です(上記のものもRRD命令部をシフト化して数clkの短縮は可能ですが)。
今回の問題では入力範囲が0..99なのでこのような分数演算の手法では誤差を1%未満にする必要があります。私も13/128でやってみたところ誤差が1%以上なので回答が途中からズレた結果になりました。
また、整数演算なので誤差が1%未満であっても誤差の範囲内の変動で回答が影響を受けないように inc a で微調整されています。
普通に考えると16bitでシフトしたいところですが、なんと8bitのシフトや演算で処理を完結しています・・すばらしい!
私も新たなアイディアを思いついたら追記したいと思います。
★追記 2019/08/02
アイディアが浮かんだので試してみた結果をメモしておきます。
★変更 2019/08/03 {
yasuokaの日記: Re:Z80における定数10の除算は、商と余りのどちらを先に求めるべきかの記事がアップされ剰余を先に求める方法で103clk(最後にretを追加した場合)達成とのこと。
今回追記した処理に関してもまだ少しのりしろがあったので一部見直し103clkになりました^^
}
今回適用した主要なアイディアとしては、少数演算の使用と上位/下位のnibleを逆転することによる4bitシフト処理の省略です。
後者についてはピンと来ないかも知れませんが以下に概要を説明します。
- 小数点で処理
分数方式だと前回記載したように誤差が1%未満の条件で分子と分母の組合せを色々考えることになりますが、0.1を2進数で表現し、その乗算値を求めればいいのでは?と考えました。
小数点であれば分数のように組合せを考える必要が無いし、誤差は桁数に依存し一意に決まります。
また、シフトが一方向なので往復するようなシフト処理が発生しません。
下表に示すように 0.1を2進数で表すと2進数の循環小数になります。
下表の1~9(橙色部分)の合計は 0.099609 なのでここまで算出すれば1%未満という条件を満たす誤差範囲になるはずです。
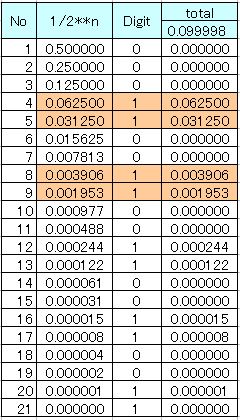
- 小数点の桁のアサイン
速度優先で計算は8bitで行うので8bit分の有効桁数を維持するために表中のNo.1~3のゼロの部分は省略してNo4をMSBに割り振ります。
この場合、16倍したことになるので最終的に上位nibleに結果が求まることになり、結果を取り出すために4回のシフト処理が必要になりますが、この問題は後述の対策で解決します。
- 循環小数の求め方
表中のNo4と5の合計を求め、1/16倍(4bitシフト)すればNo8と9の合計になります。
- 上位/下位ニブルの逆転処理
上記の循環小数のための4bitシフトでRRCAを使用することで、上位のnibleと下位のnibleが入代ります。
ここでLSB側のnibleの方を上位、MSB側のnibleを下位と考えるとシフト前の値がシフト後の値の1/16と考えることができます。
また、0.1倍した結果がLSB側のnibleに入るようになるので、前述した結果を取り出す際の4回のシフト処理が不要になります。
- 加算部の処理
表中のNo.4,5にNo.8,9を加算する際は、MSB側の下位nibleから上位nibleへ桁上り(キャリー)が発生するか否かが必要な情報であり、キャリーが発生した場合、LSB側の上位nibleに反映するために、No.8,9を加算後にキャリ付き加算(ADC)を実行しています。
- 剰余の計算
商が求まったら、商の10倍を入力値から減算して余りを算出しています。
|
★追記 2019/12/27
下記の変更で3ステート速くなり、サイズも1バイト小さくなります。
5F LD E,A ; 4 81 ADD A,C ; 4 3E 00 LD A,0 ; 7 8B ADC A,E ; 4 ↓ 81 ADD A,C ; 4 3F CCF ; 4 99 SBC A,C ; 4 3C INC A ; 4 |
★追記 2021/12/03
上記の変更でEregが非破壊になりました。更にCregを使用している3箇所をHreg使用に変更することでCregも非破壊にできます。
★追記 2019/08/07
分数方式についての考察を少し書いてみます。
初めに前回の小数点方式について動作を判り易く図解してみます。
下図で一番上に書いてある「x 1.5」の行は被除数を1.5倍したものです。
0.1を2進数で表すと上記のように「0001100110011・・・」の循環小数になるので「1.5倍」の数を4ビットずつシフトしながら無限回並べたものの合計になります。
上の小数点方式の説明で「上位/下位ニブルの逆転処理」と書いた部分でキャリーを足している対象は正確に言うと下図の「整数部分」になります。
| 小数点方式の処理イメージ図 |
|
|
因みに4bit周期の循環小数なのでうまくやれば誤差無しに計算可能で(循環部で桁上りした場合、下の桁からも必ず桁上りしてくるので)、小数点部分を正確に求められれば、小数点の上位3bitの2倍と8倍を足すことで余りの値も計算結果から求められるはずなのですが、
- 8bitでは処理が難しい
シフトする塊が被除数の3倍なので桁落ちせずに計算するには 99 x 3 = 297 まで扱う必要があり、1バイト処理では難しい
- 小数部からの余りの取り出し処理
現状の商から余りを求める部分と比較し大きな効果が出るとは思えない。
の理由から断念しました。
話を分数方式に戻すと分母が2のべき乗の場合、分子のビットパターンは結局上記の0.1の循環小数と同様になり(分母が2のべき乗なら分子は0.1の循環小数のパターンをシフトしたものの近似になるのは当然)、処理内容は前回書いた小数点方式とほぼ同様になります。
試しに 25.5 / 256(1バイトなので判り易い)を例にすると下図のように1.5倍したものを RLCA で4回左シフトし、整数部は下位4bitに折り返した形になります(折り返し部分は不要なのですが、上の小数点方式の観点で見れば、演算精度を上げる方向に作用するのでワザワザ削除する必要はない)。
シフト前とシフト後の値の合計を取り、発生したキャリーを整数部に加える処理となり、前回書いた小数点方式と処理内容は同じになります。
小数点方式も同様ですが(ウルトラCのアイディアがあれば)循環小数点部分の処理の高速化については検討の余地があるかもしれません。
| 分数方式(25.5/256)の処理イメージ図 |
|
|
★追記 2019/09/16
「Z80における2進→BCD変換」というお題を見つけたのでWeb上のMSX環境で凸撃兵さんが作られたのものを改造してMSXPen環境で確認してみました。
★追記 2023/04/22
下記の記事で 8bit 符号無し整数の高速な乗算方法を提案しました。


)

){kind=link}
){kind=link}
10の割算処理について、改善処理を追記しました。
by skyriver (2019-08-02 23:47)
このページに改善版を追記した後に
https://srad.jp/~yasuoka/journal/631908/
に更に高速な処理が記載されていることに気付きこちらも少し改善してみました。
by skyriver (2019-08-03 09:48)
2のべき乗を分母にした分数方式についての考察を追記しました。
by skyriver (2019-08-07 23:10)
なんと誤差1%以上の分数計算(13/128)方式で最速記録が更新されました。すごぃ。
「2019/08/07 追記」で書いた「循環小数点部分の処理の高速化」の一つの方法として「000110011」を「0001101」に丸めることにあったとは驚きです。
https://srad.jp/~yo4/journal/632067/
by skyriver (2019-08-09 07:50)
ソースを見比べると13/128方式は商が求まるタイミングは同じですが商から余りを算出する部分でCレジで4倍値を使いまわすことで早くなっている・・ということですね。
by skyriver (2019-08-09 08:14)
誤差1%未満が必要条件だと思ってましたが13/128で問題なかったということが気になったので以前、13/128で評価した時のソースを使って検証してみました。
このソースはまずはアルゴリズムの確認のために16bitでロスレスで処理しています。
結果は 「06 03 06 05」で1個ズレ(64の余りが5になった)、その後終わりまでズレています。
LSBをゼロにしたことが影響したのかと思い AND 0FEHにしてやってみましたが結果は同じでした。
8bit処理で右シフトの度に下位bitを捨てていることが補正になり、ずれが発生しなかったものと思われます。
by skyriver (2019-08-09 18:15)
やはり最初に0FEHでANDしていることが補正になっていました。
シフト途中の加算をLSB付きの値(=Breg)で行うと69で10の桁が7になってしまいました。
by skyriver (2019-08-11 17:14)